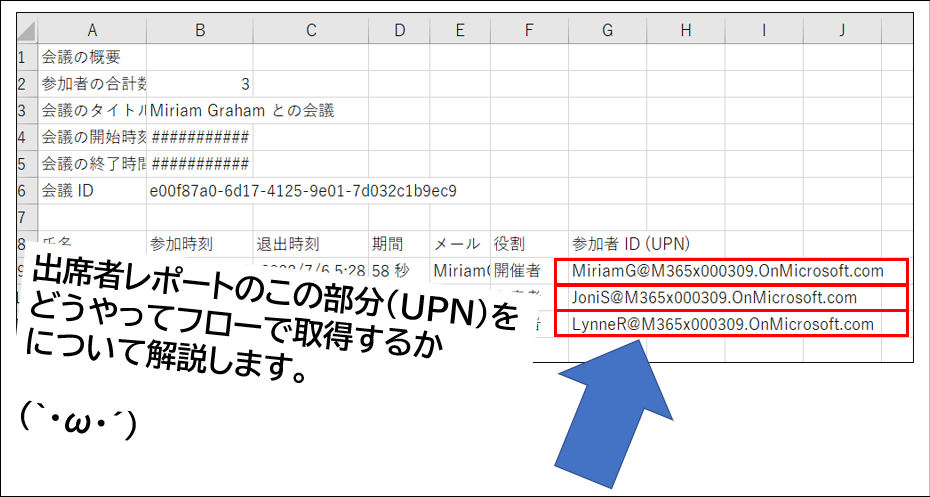
ましゅまろで質問を頂いた、掲題のフローの解説編です。
フローをGitHubで公開しました。下記リンク先からダウンロードしてください。
7/9(土)にフローの変数を見直しました。最終的なフローの出力は変わりませんが、このフローのロジックを参考にしたいかたは最新版をダウンロードしてください。
github.com
解説するフロー図
アクションの設定を閉じた状態のフロー図

開いた状態のフロー図

フローを使用する準備
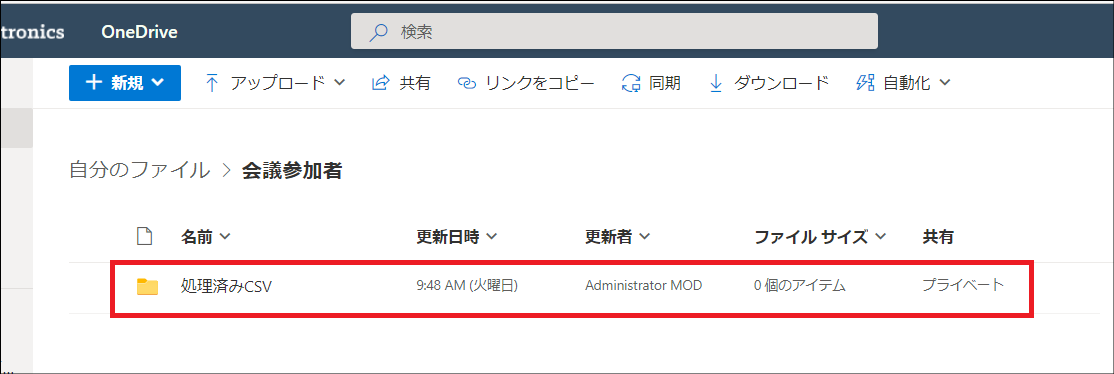
このフローではファイルの入力・出力ともOneDrive for Business 上のフォルダを使います。OneDrive for Businessにこのフロー用のフォルダを作成します。
ルートフォルダに「会議参加者」という名前のフォルダを作成します。これが入力用のフォルダです。

「会議参加者」フォルダを開いてそのなかに「処理済みCSV」という名前のフォルダを作成します。これが出力用のフォルダです。
ステップごとの説明
「ファイルが作成されたとき」トリガー
これは「OneDrive for Business」>「ファイルが作成されたとき」トリガーです。OneDrive for Business 内の指定したフォルダでファイルが作成されたときにフローを実行するトリガーです。
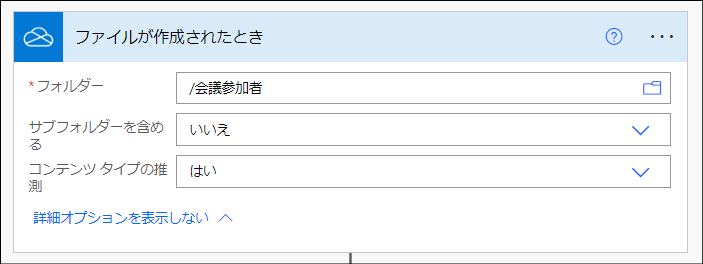
「フォルダー」欄は先ほど作成した「会議参加者」フォルダを指定します。
「サブフォルダーを含める」欄は既定値である"はい"から"いいえ"に変更します。目的は「会議参加者」フォルダのサブフォルダである「処理済みCSV」フォルダでのファイル作成を対象外にするためです。
「ファイル コンテンツの取得」アクション
これは「OneDrive for Business」>「ファイル コンテンツの取得」アクションです。このアクションで「会議参加者」フォルダにアップロードされたファイルを取得します。
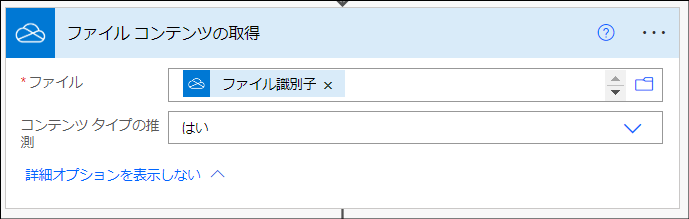
"parameters": {
"id": "@triggerOutputs()?['headers/x-ms-file-id']",
"inferContentType": true
},
「作成-CSVの全行」アクション
これは「データ操作」>「作成」のアクションです。CSVのデータを取得します。

"inputs": "@split(body('ファイル_コンテンツの取得'),decodeUriComponent('%0A'))"
このアクションで何をしているかを詳しく解説します。
「ファイル コンテンツの取得」アクションでCSVファイルのデータを取得したとき、フローからみるとこのファイルは一行のテキストです。列や行は認識していません。
そのため、この「作成-CSVの全行」アクションではsplit関数を使用してCSVの行を値とする配列に変換しています。
decodeUriComponent('%0A') は改行を表す特殊文字「%0A」をデコードしていることを表します。テキストで「%0A」や「\n」と書いてもフローはそれを改行だと認識できません。「改行」をフローに認識させるために必要な操作であるととらえてください。
出力:
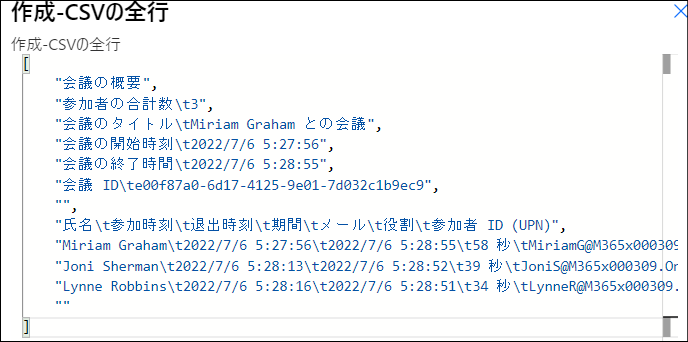
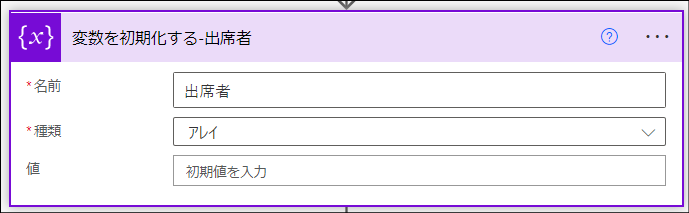
「変数を初期化する-出席者」アクション
これは「変数」>「変数を初期化する」アクションです。このフローの最終的な出力である出席者情報を格納する配列変数です。ここで値を空白の状態で初期化します。
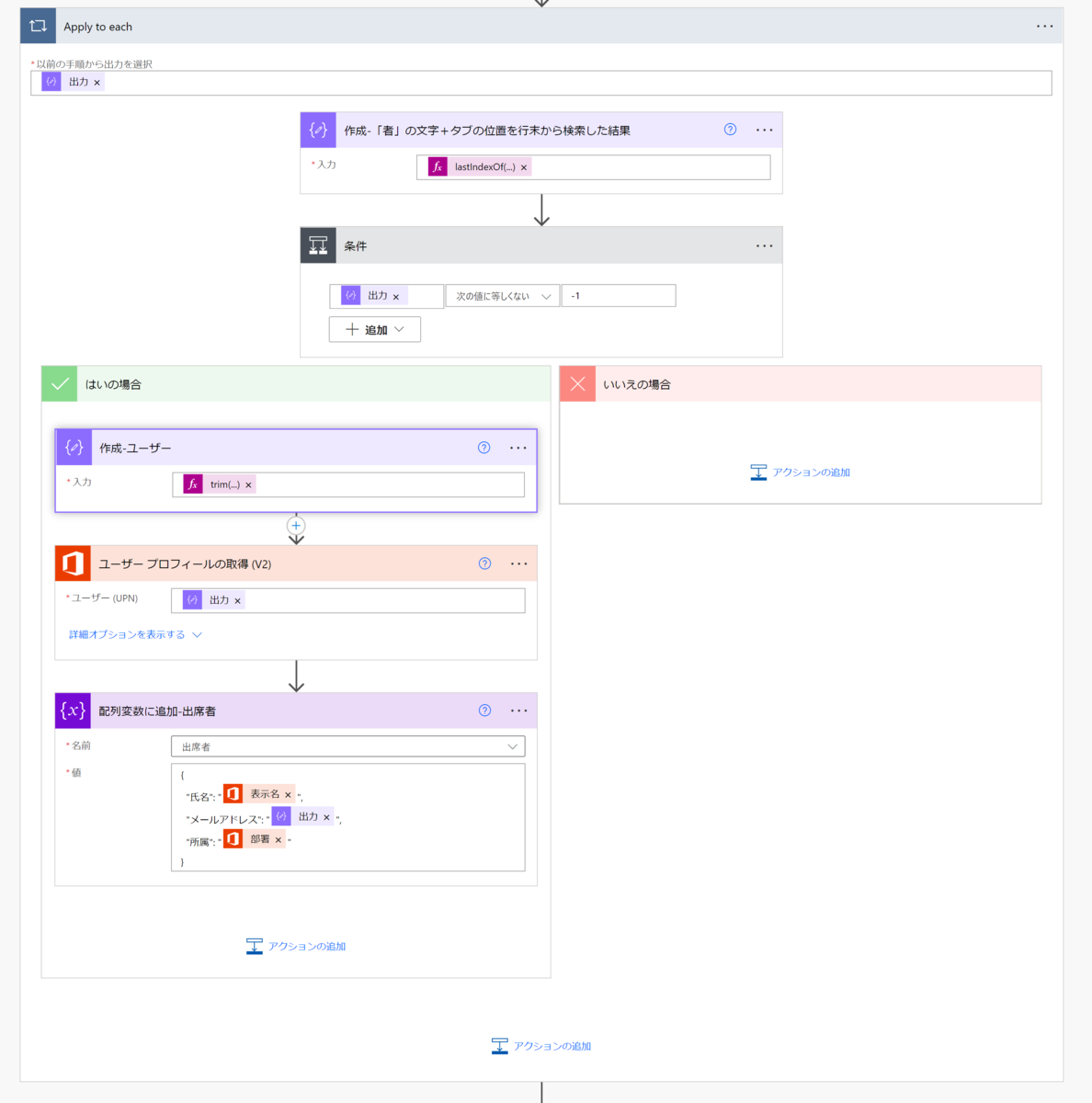
「Apply to each」アクション
これは「コントロール」>「Apply to each」アクションです。CSVの行単位で繰り返し処理を行い、出席者の配列変数にデータを格納します。
繰り返し処理の入力情報は「作成-CSVの全行」アクションで取得した配列です。
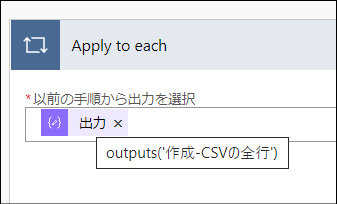
これのことですね。この配列の行ごとに繰り返し処理を行います。
繰り返し処理内のアクションをステップごとに解説します。
「作成-「者」の文字+タブの位置を行末から検索した結果」アクション
これは「データ操作」>「作成」のアクションです。

このアクションはその行のどこに「"者"という文字とタブを表す特殊文字をつなげた文字」があるか(= 行頭から何文字目か)を検索した結果を表します。lastindexof 関数を使用しているため、検索は行末から行います。
"inputs": "@lastIndexOf(item(),concat('者',decodeUriComponent('%09')))",
「条件」アクション
これは「コントロール」>「条件」アクションです。その行に「"者"という文字とタブを表す特殊文字をつなげた文字」があるかどうかで処理を分岐します。この文字を探す理由については後述します。
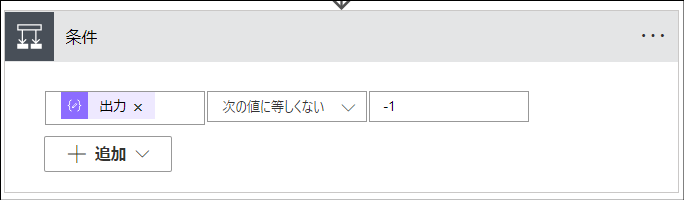
- outputs('作成-「者」の文字+タブの位置を行末から検索した結果')
- 次の値に等しくない
- -1
詳しく解説します。
「作成-「者」の文字+タブの位置を行末から検索した結果」アクションで定義した「"者"という文字とタブを表す特殊文字をつなげた文字」を検索するlastIndexOf関数によって、行のどこに該当する文字が登場するか検索が行われます。
この検索が探している対象は、出席者レポートにおける「役割」列の値の部分(= 開催者または発表者)です。
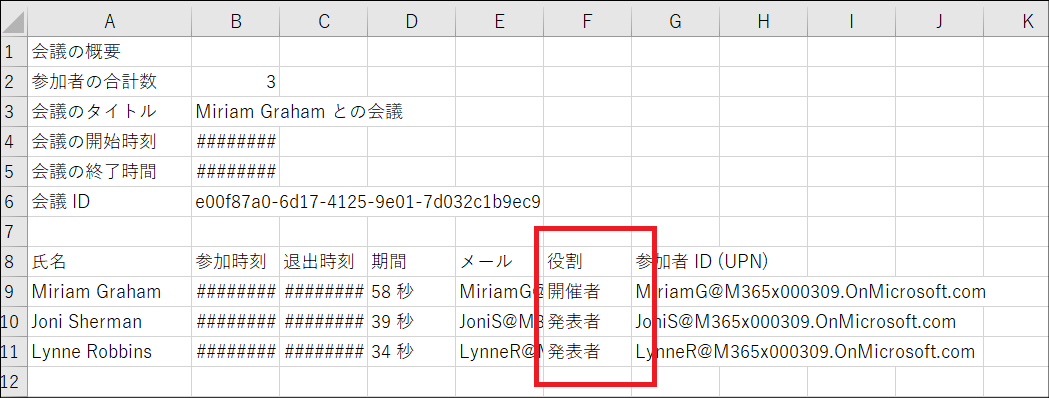

lastIndexOf関数は検索対象の文字が見つかればその文字が行頭から何文字目にあるかという値を返します。検索対象の文字が無い場合は「-1」を返します。
そのためこの条件アクションでは、lastIndexOf関数の結果が「-1」に「等しくないかどうか」でどちらの分岐に進むかを判定しています。
条件に対する結果が True、 つまり、lastIndexOf関数の結果が「-1」に「等しくない」場合は「はいの 場合」の分岐に進みます。これは出席者情報を含む行に対する分岐です。
条件に対する結果が False、つまり、lastIndexOf関数の結果が「-1」に「等しい」場合は「いいえの 場合」の分岐に進みます。これは出席者情報を含まない行に対する分岐です。
注意:この判定方法は「氏名の末尾が "者" であるユーザー」がいる場合に誤作動を起こします。そのためこのフローを運用で使う場合は判定条件を見直してください。
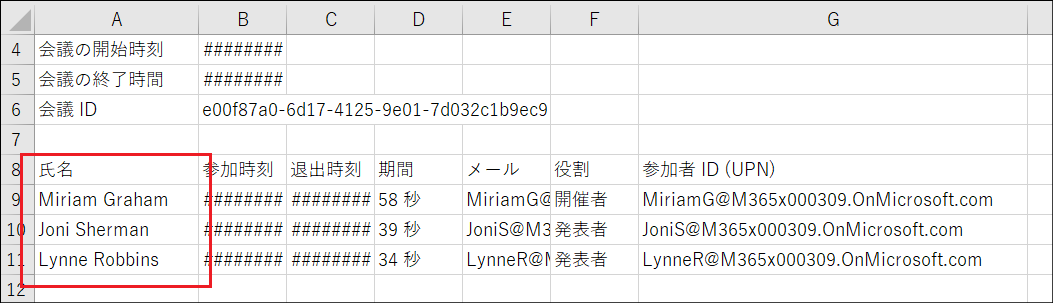
「はい」に分岐した場合
true(= 出席者情報を含む) である場合は「はい」に分岐します。この分岐では出席者の配列変数にデータを追加します。

まずは、substring関数によって出席者のUsePrincipalNameを取得します。

"inputs": "@trim(substring(item(), add(outputs('作成-「者」の文字+タブの位置を行末から検索した結果'), 2)))",
出席者レポートのこの部分のテキストを取得するということです。
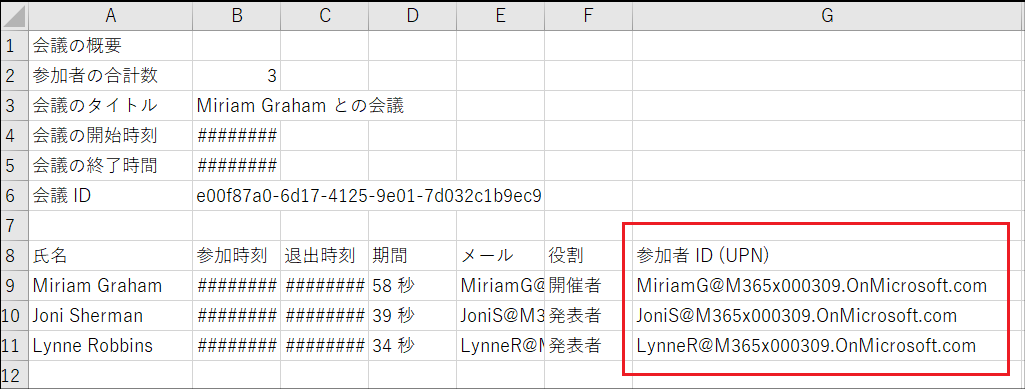
次に、先ほど取得したUserPrincipalNameを入力情報としてユーザープロファイルの検索を行います。このアクションの目的は出席者の表示名と所属部署を取得することです。
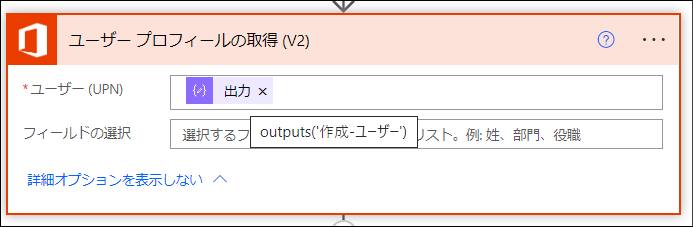
次に、配列変数にデータの追加を行います。
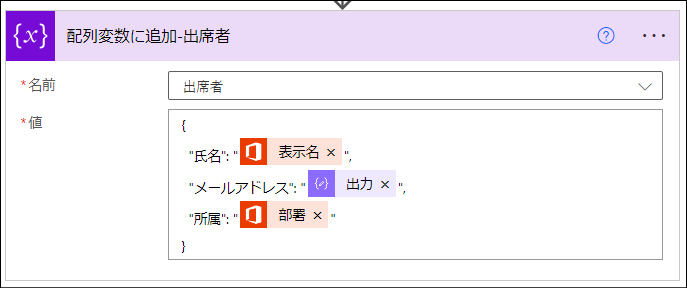
"inputs": {
"name": "出席者",
"value": {
"氏名": "@{outputs('ユーザー_プロフィールの取得_(V2)_')?['body/displayName']}",
"メールアドレス": "@{outputs('作成-ユーザー')}",
"所属": "@{outputs('ユーザー_プロフィールの取得_(V2)_')?['body/department']}"
}
}
「いいえ」に分岐した場合
false(= 出席者情報を含まない) である場合は「いいえ」に分岐します。この分岐では何も行わずに後続の工程にフローを進めます。

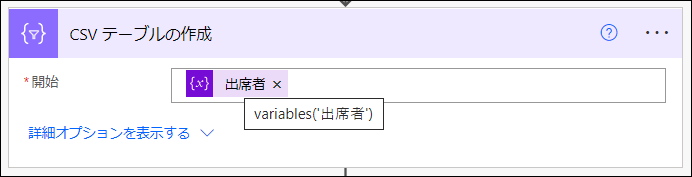
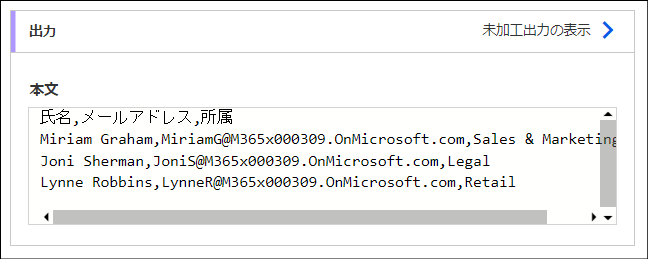
「ファイルの作成」アクション
これは「OneDrive for Business」>「ファイルの作成」アクションです。このフローの最終的な出力としてCSVファイルを出力します。
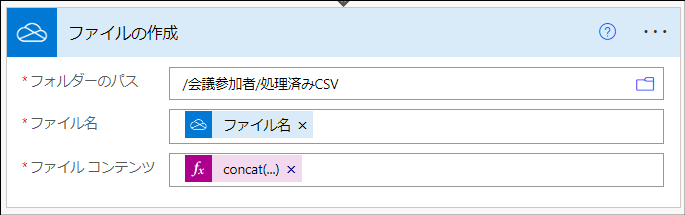
ポイントはCSVの文字化けを避けるために、出力するbodyの頭にBOMをつけているところです。「EF BB BF」はUTF-8のBOMの16進表現を表しています。
"parameters": {
"folderPath": "/会議参加者/処理済みCSV",
"name": "@triggerOutputs()?['headers/x-ms-file-name-encoded']",
"body": "@concat(decodeUriComponent('%EF%BB%BF'),body('CSV_テーブルの作成'))"
}
この文字化け回避についてはこちらのフローでも触れています。
wataruf.hatenablog.com
これでフローの解説は以上です。
今回は以上です。