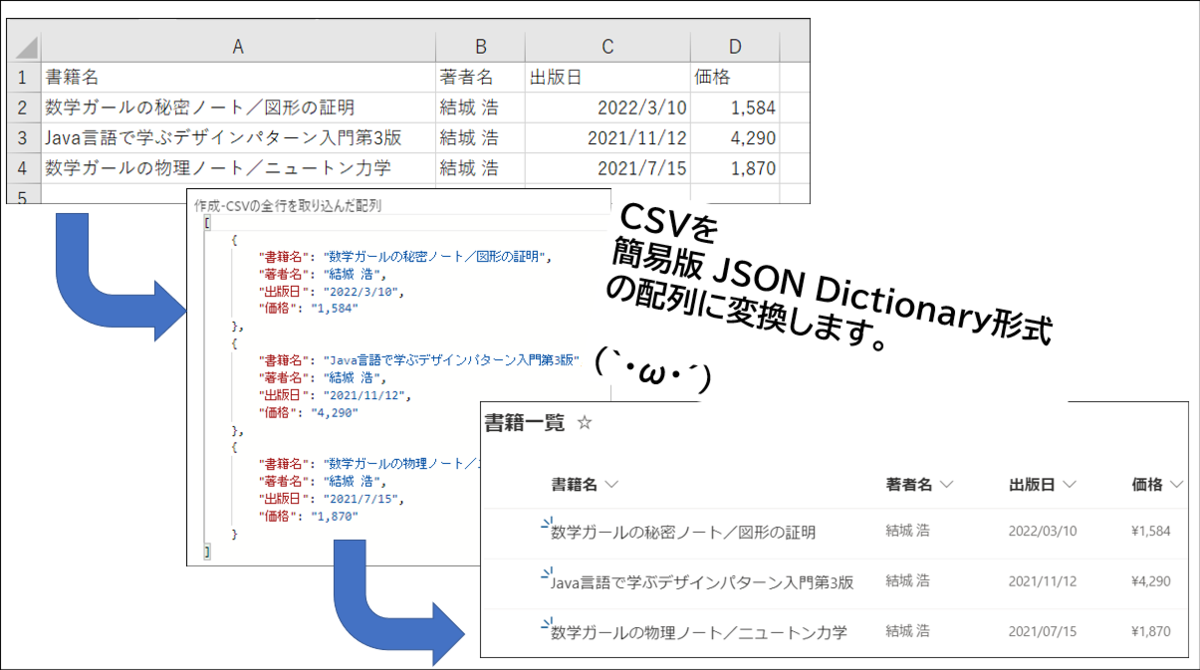
掲題のフローの解説編その1です。
フローをGitHubで公開しました。下記リンク先からダウンロードしてください。
github.com
- 解説の経緯
- この回で解説する範囲のフロー図
- この回で解説するフローの処理概要
- ステップごとの解説
- 今回の範囲で得られた出力
- 次回解説する範囲はデータ部分の処理です。
- 2022/8/28追記:解説編その2を投稿しました。
解説の経緯
今回の投稿は概要編 の続きです。
この回で解説する範囲のフロー図
アクションの設定を閉じた状態のフロー図
この回で解説する範囲は、フロー全体のうち下図の赤枠の部分です。
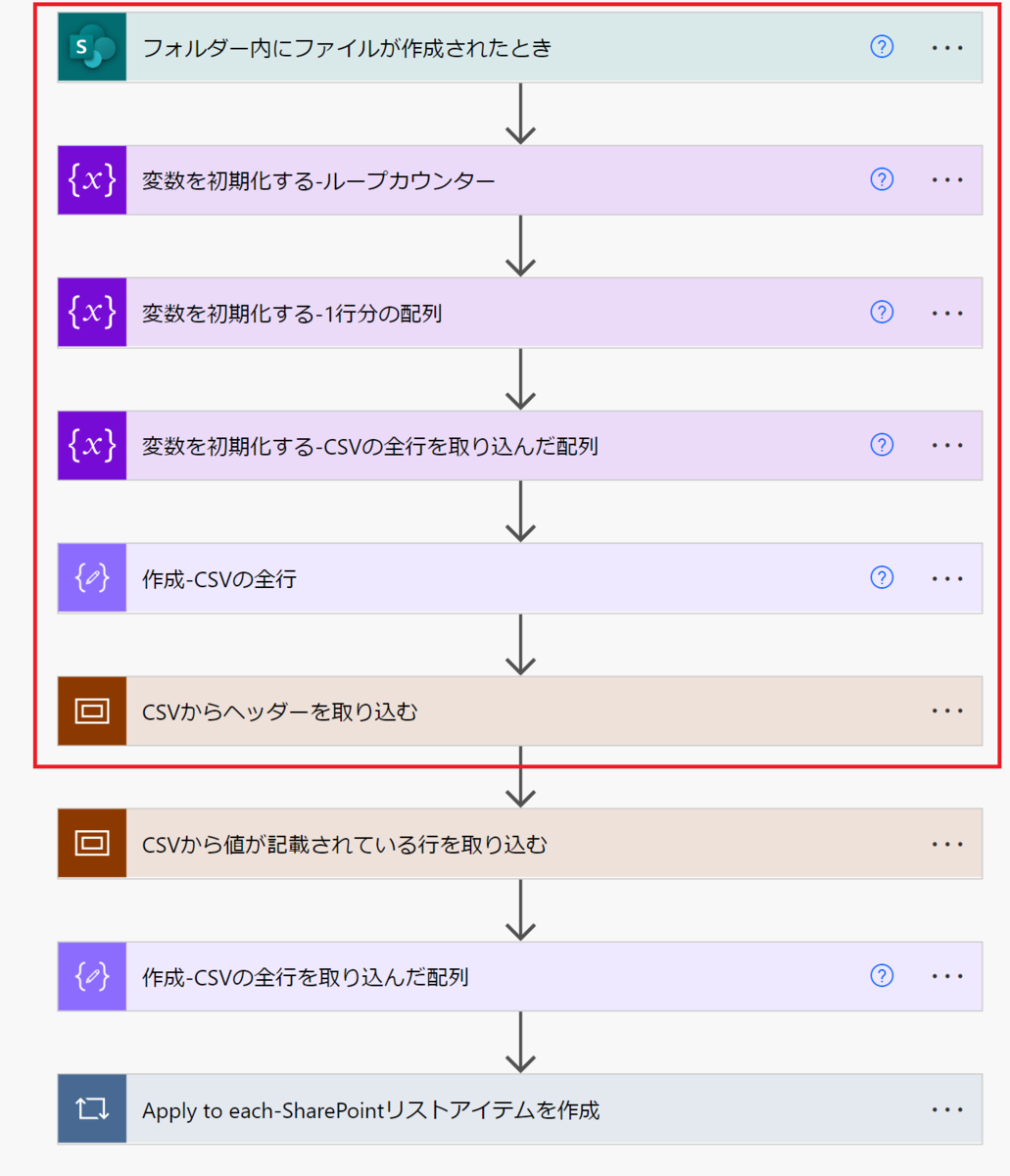
開いた状態のフロー図
下図は赤枠部分のアクションを開いたフロー図です。
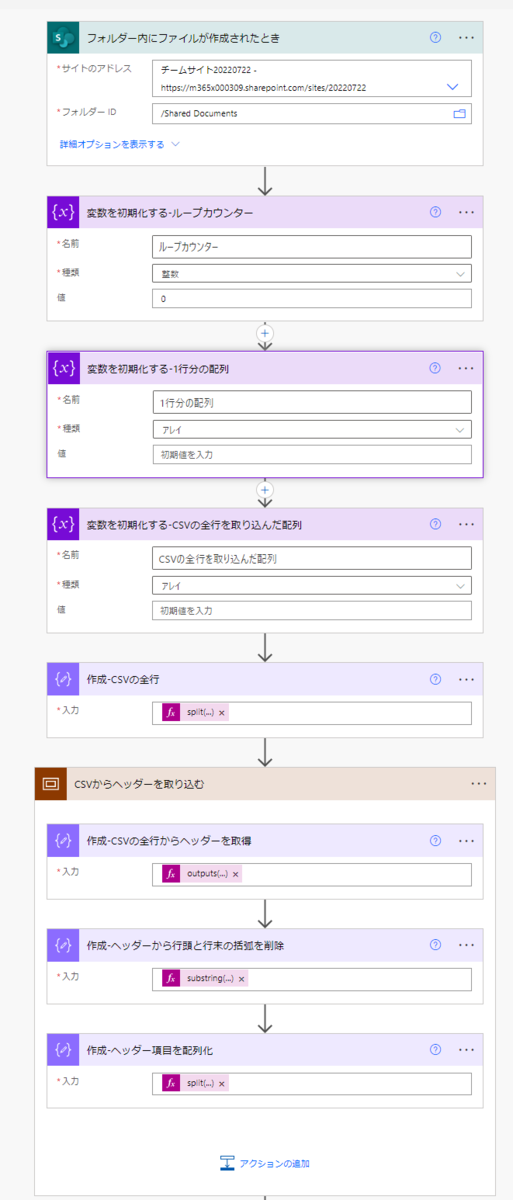
この回で解説するフローの処理概要
今回の範囲で解説するアクションの流れは以下の通りです。
- SharePointライブラリからCSVの中身を取得する
- この時点で取得するデータは1行のテキスト
- データを改行コードでテキスト分割する
- その結果として得られるのは行単位で分割されたテキストの配列
- 配列のひとつめのデータを取得する。これをカンマでテキスト分割する
- その結果として得られるのは列項目ごとで分割されたテキストの配列
つまり、今回の範囲で得られる出力は「列名の配列」です。
それでは今回の範囲のフローをステップごとに解説します。
ステップごとの解説
「フォルダー内にファイルが作成されたとき」トリガー
「SharePoint」>「フォルダー内にファイルが作成されたとき」トリガーです。
このトリガーはライブラリにファイルがアップロードされたときにフローを実行します。
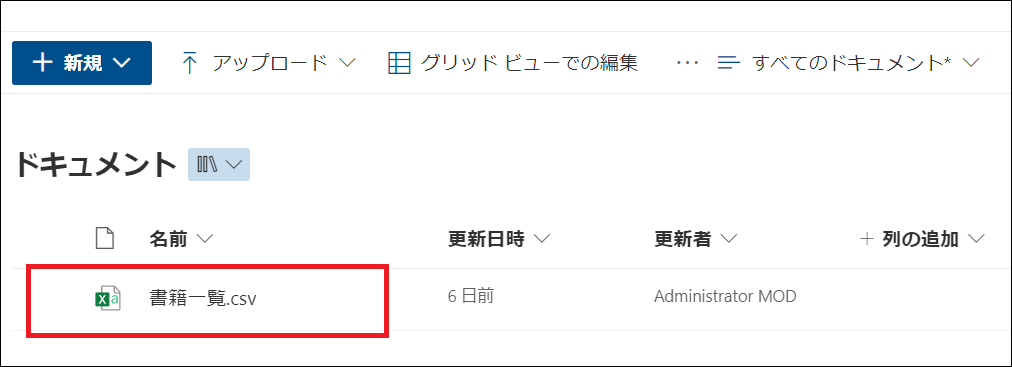
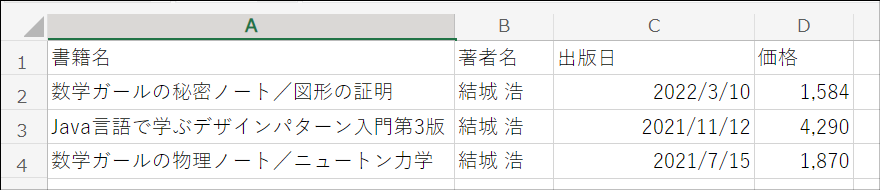
解説で使用するCSVの中身は下図の通りです。
「変数を初期化する-ループカウンター」アクション
「変数」>「変数を初期化する」アクションです。

このループカウンター変数は次回の解説する範囲のステップで使用します。
「変数を初期化する-1行分の配列」アクション
「変数」>「変数を初期化する」アクションです。

この変数についてもループカウンターと同じく次回解説する範囲で使います。

「作成-CSVの全行」アクション
「データ操作」>「作成」アクションです。ここではトリガーのアクションから取得したデータを行ごとに区切ります。

"inputs": "@split(triggerOutputs()?['body'], decodeUriComponent('%0D%0A'))"
CSVから読み込んだデータはその時点では1行のテキストです。
※トリガーの出力をテキストエディタで表示しています
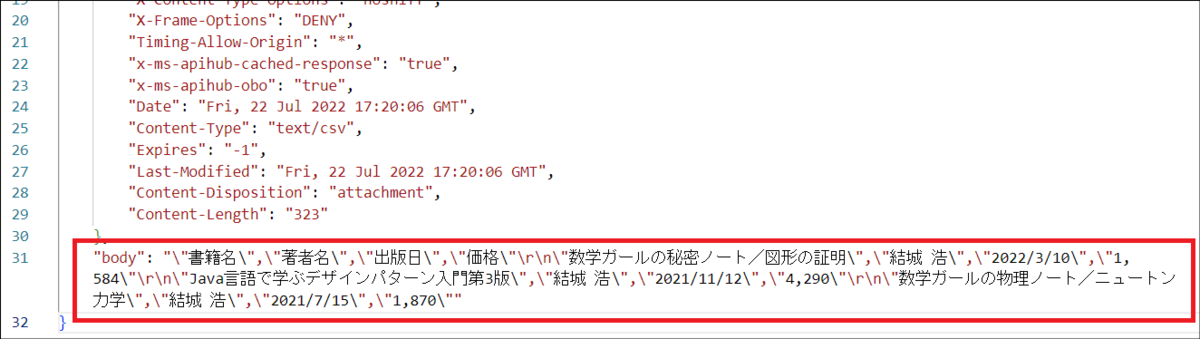
このアクションでは、CSVから取得した1行のテキストをsplit関数を使ってテキスト分割します。分割を行う区切り文字として使用しているのが「decodeUriComponent('%0D%0A'))」から返される値です。
decodeUriComponent関数はURLエンコードされた文字列をデコードする関数です。
ここでデコードしているのは「%0D%0A」という文字列です。デコードした結果得られる値が改行コードを表す「r\n\」です。手入力で「r\n\」を入力してもPower Automateは改行コードとして認識できないため「decodeUriComponent('%0D%0A'))」という指定をしています。

「CSVからヘッダーを取り込む」スコープ
「コントロール」>「スコープ」アクションです。
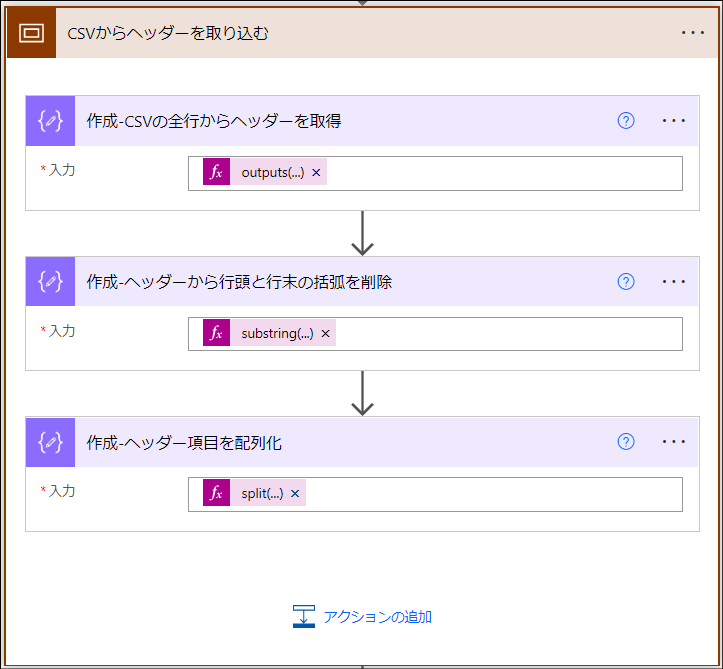
このスコープでは3つのアクションを使ってCSVの列項目を配列に変換します。
処理内容は下図の通りです。列名にダブルクォーテーションやカンマが使われている場合にそれらを消さないようにする意図でこのような処理にしています。

「作成-CSVの全行からヘッダーを取得」アクション
「データ操作」>「作成」アクションです。

"inputs": "@outputs('作成-CSVの全行')?[0]
このアクションでは配列のひとつめのデータを取得しています。これはこのCSVの列名を表しているテキストです。

「作成-ヘッダーから行頭と行末の括弧を削除」アクション
「データ操作」>「作成」アクションです。

"inputs": "@substring(outputs('作成-CSVの全行からヘッダーを取得'),1,sub(length(outputs('作成-CSVの全行からヘッダーを取得')),2))"
substring関数を使って先頭と末尾の文字以外を取得しています。replace関数でダブルクォーテーションを消そうとすると目的以外の文字を消してしまう場合があるためこの方法を採用しています。

「作成-ヘッダー項目を配列化」アクション
「データ操作」>「作成」アクションです。

"inputs": "@split(outputs('作成-ヘッダーから行頭と行末の括弧を削除'),'\",\"')"
split関数でテキスト分割をしています。区切り文字は「\",\"」の部分です。「\」はエスケープ文字です。

今回の範囲で得られた出力
今回の範囲で得られた出力は「列名の配列」です。
列名の配列:

次回解説する範囲はデータ部分の処理です。
次回はこの部分を処理します。
 ]
]
データ部分と列名を紐づけてこんな配列をつくります。

今回は以上です。