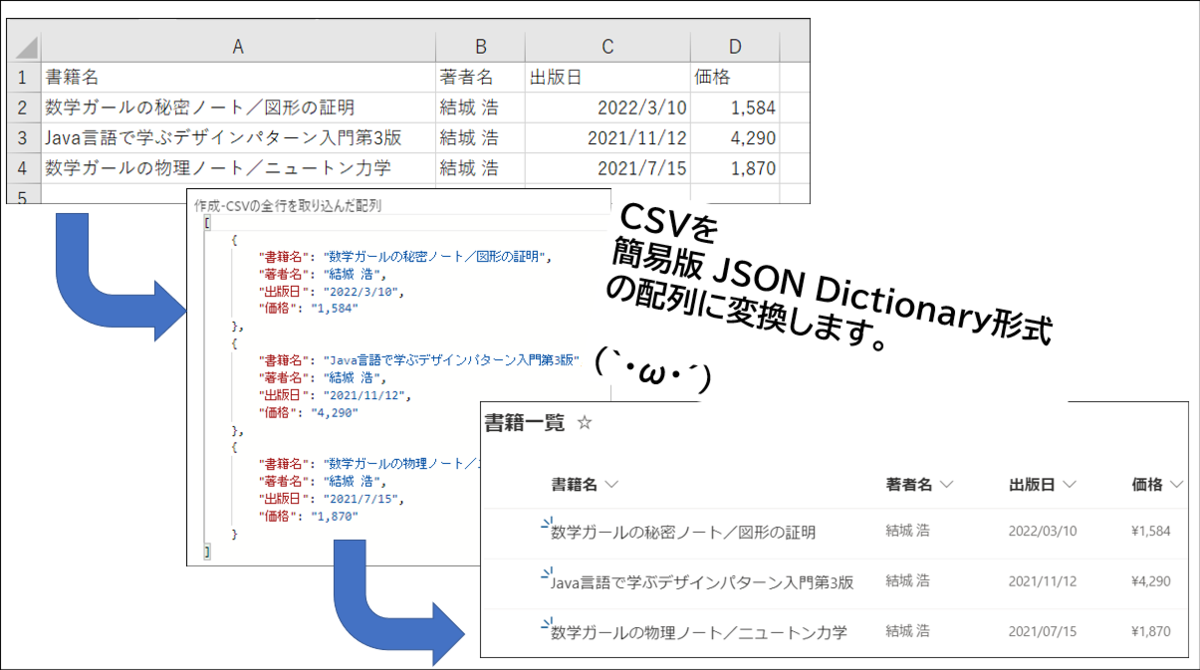
掲題のフローの解説編その2です。
フローをGitHubで公開しました。下記リンク先からダウンロードしてください。
github.com
この回で解説する範囲のフロー図
アクションの設定を閉じた状態のフロー図
この回で解説する範囲は、フロー全体のうち下図の赤枠の部分です。
開いた状態のフロー図
下図は赤枠部分のアクションを開いたフロー図です。
この回で解説するフローの概要
今回の範囲で解説するフローの概要は以下の2つです。
- "列名の配列"と"データ部分の配列"を入力としてJSON配列を得る
- そのJSON配列を入力としてSharePointにリストアイテムを投稿する
"列名の配列"と"データ部分の配列"を入力としてJSON配列を得る
"列名の配列"は解説編その1 の出力であるこの配列です。

"データ部分の配列"は今回解説する範囲の冒頭にでてくるこの配列です。

上記の2つを入力として、配列操作によって列名をプロパティにしたJSON配列を作ります。
それによって出来上がるのがこの配列です。

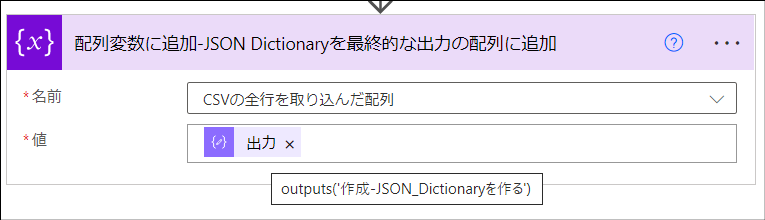
そのJSON配列を入力としてSharePointにリストアイテムを投稿する
作成したJSON配列を入力にして[SharePoint Online]>[項目の作成]アクションを使ってSharePointリストにアイテムを投稿します。CSVの1行につき1アイテムを投稿するため、Apply to each アクションを使った繰り返し処理をします。
ステップごとの解説
"列名の配列"と"データ部分の配列"を入力としてJSON配列を得る
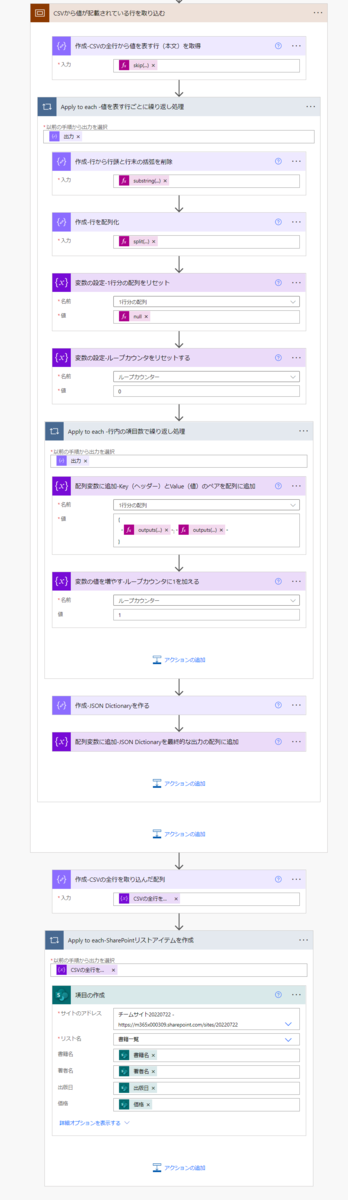
この章の解説対象は「CSVから値が記載されている行を取り込む」という名前のひとつのスコープです。
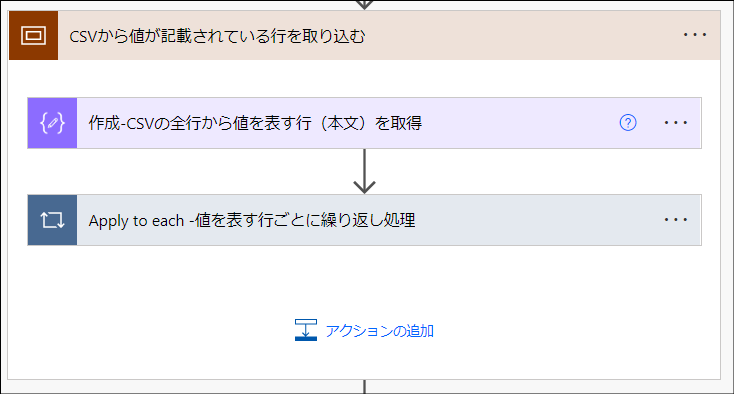
まずは、CSVにあるデータ部分の行を取得します。そのために使うのが「データ操作」>「作成」アクションで使用しているskip関数です。
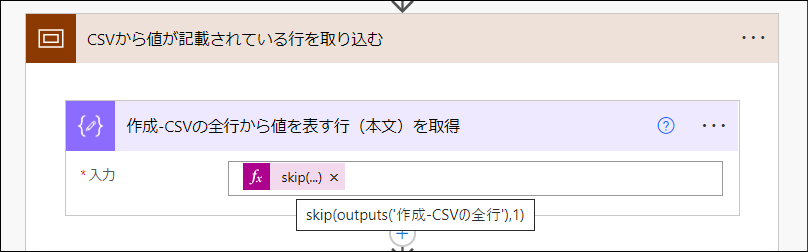
skip(outputs('作成-CSVの全行'),1)
skip関数についてはこの投稿でも解説しています。skip関数を使うと配列(アレイ)の先頭から任意の数の要素を削除することができます。
この作成アクションの出力が以下の配列です。解説編その1の範囲で改行でスプリットしているため、CSVのデータ部分の行と配列の要素が1対1になっています。

次に、CSVのデータ部分の行ごとに繰り返し処理を行います。
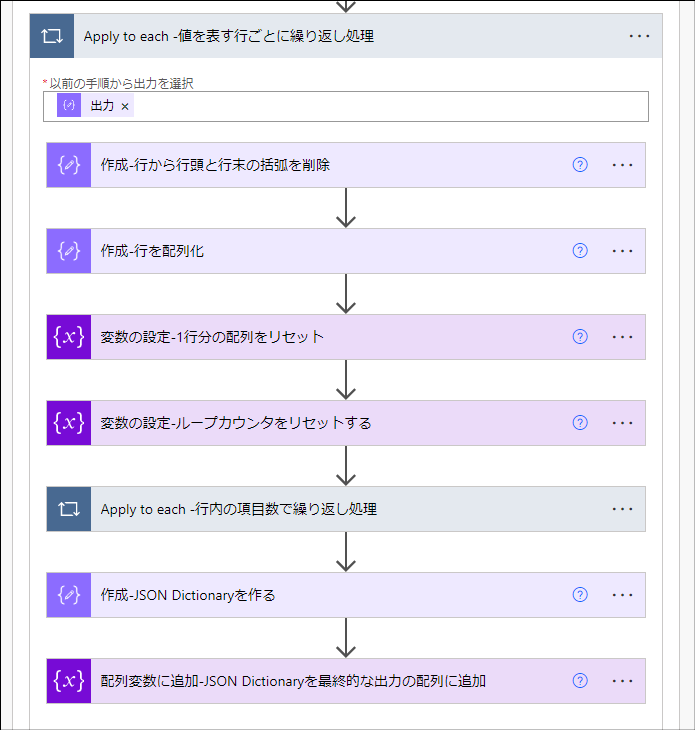
この繰り返し処理でループが1回まわるたびに、JSON配列を格納している変数の要素がひとつ追加されます。(= 下図の赤枠の部分が追加されます)
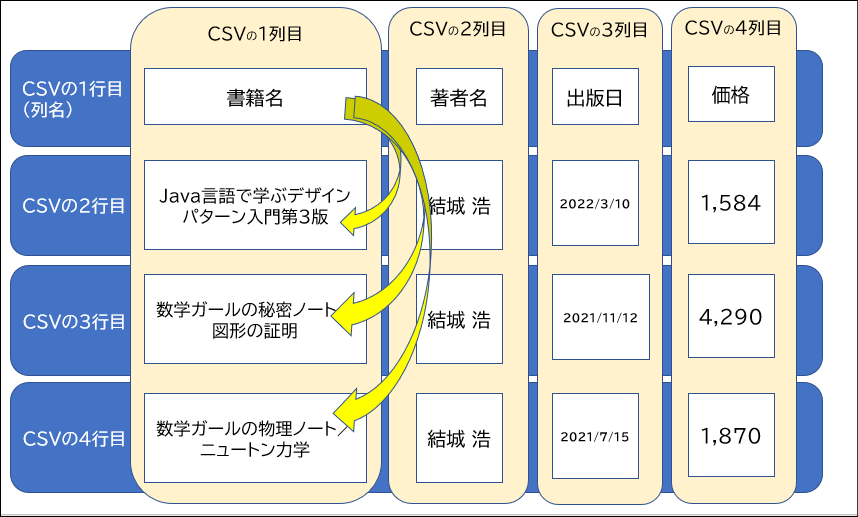
ポイントはどうやって列名(プロパティ)と値(データ)を紐づけているかです。
そのからくりは下図の通りです。左から何番目にあるかで判断しています。例えば、"列名を表す1行目"にある1列目の「書籍名」と"データを表す2行目以降"にある1列目が紐づいていると判断しています。この"何番目の列であるか"の判断をフローのアクションではループカウンターの変数を使って行っています。
この繰り返し処理で使用するアクションを解説します。
「作成-行から行頭と行末の括弧を削除」アクション
このアクションは「データ操作」>「作成」アクションです。

substring(item(),1,sub(length(item()),2))
substring関数を使って先頭と末尾のダブルクォーテーションを除いた文字列を取得します。
「作成-行を配列化」アクション
このアクションは「データ操作」>「作成」アクションです。

split(outputs('作成-行から行頭と行末の括弧を削除'),'","')
「"」「,」「"」の3文字の並びを区切り文字として文字列を配列にします。
つまり以下の文字列が、、
![]()
こうなります。CSVをExcelで開いたときの1セルにあたるデータが配列の1つの要素になったイメージです。

ここでのポイントはsplit関数によって「文字列の配列化」と「不要な文字列の削除」を同時に行ったことです。split関数を後者の「不要な文字列の削除」の目的で活用できることは覚えておきたいポイントのひとつです。
また、2文字以上の並びを区切り文字として指定できることもポイントです。
「変数の設定-1行分の配列をリセット」アクション
このアクションは「配列」>「変数の設定」アクションです。
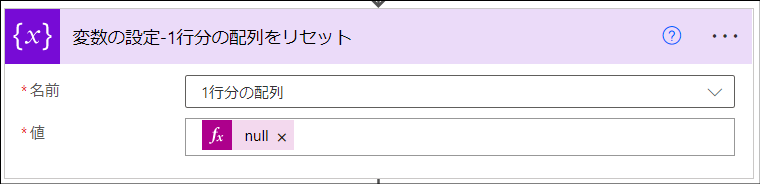
配列変数「1行分の配列」を空白値でリセットします。この配列変数は下記の赤枠の要素を格納するために使います。
「変数の設定-ループカウンタをリセットする」アクション
このアクションは「配列」>「変数の設定」アクションです。
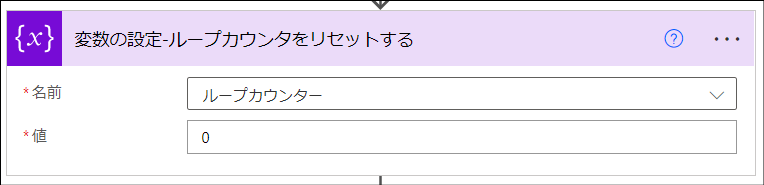
後続の「Apply to each -行内の項目数で繰り返し処理」アクションで使用するループカウンタをリセットします。
「Apply to each -行内の項目数で繰り返し処理」アクション
このアクションは「コントロール」>「Apply to each」アクションです。
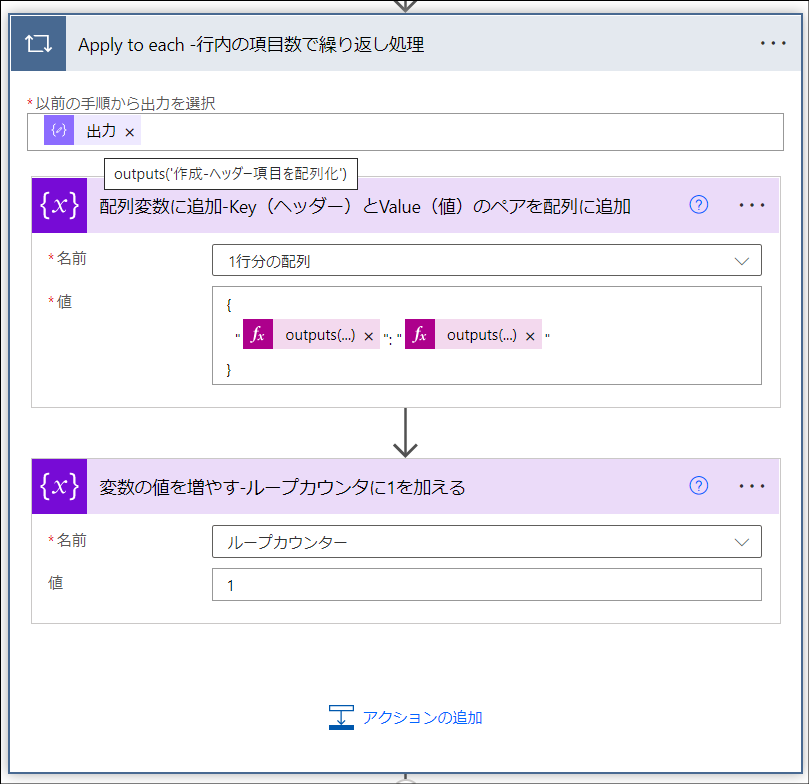
このアクションによって下記の赤枠1つ分のデータを作ります。
このApply to each のインデクサは配列変数「作成-ヘッダー項目を配列化」です。これは解説編その1の範囲でデータを格納した配列変数です。列の個数だけ繰り返し処理を行うことを表します。

ちなみに配列変数「作成-ヘッダー項目を配列化」の中身は下図の通りです。

「データ操作」>「選択」アクションを使って配列を作成します。このアクションで行っていることは後続のアクションで簡易版JSON Dictionary形式の配列変換をするための前準備です。
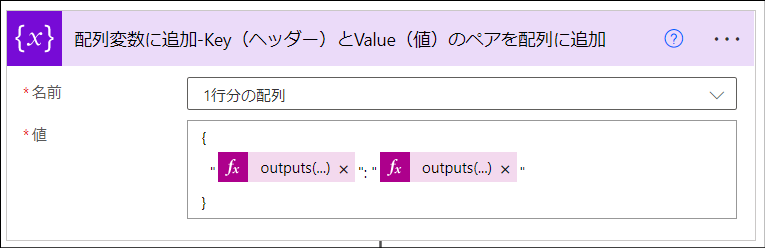
"name": "1行分の配列",
"value":
{
"@{outputs('作成-ヘッダー項目を配列化')?[variables('ループカウンター')]}": "@{outputs('作成-行を配列化')?[variables('ループカウンター')]}"
}
ループカウンターの数値を1つ増やします。そして次のループに進みます。列の個数だけループが回りきったらこのアクションは完了です。

この章で解説したアクションの出力は以下の通りです。

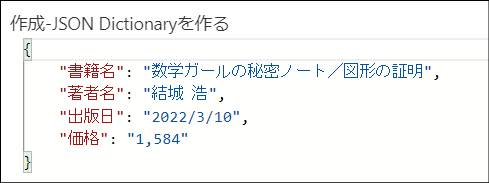
「作成-JSON Dictionaryを作る」アクション
このアクションは「データ操作」>「作成」アクションです。

前述のアクションで作成した配列を簡易版JSON Dictionary形式の配列に変換します。
つまりこの配列が、、

こうなります。
「簡易版JSON Dictionary形式の配列とは何か?」や「その形式にする目的は何か?」という解説は下記のブログ記事を参照ください。
wataruf.hatenablog.com
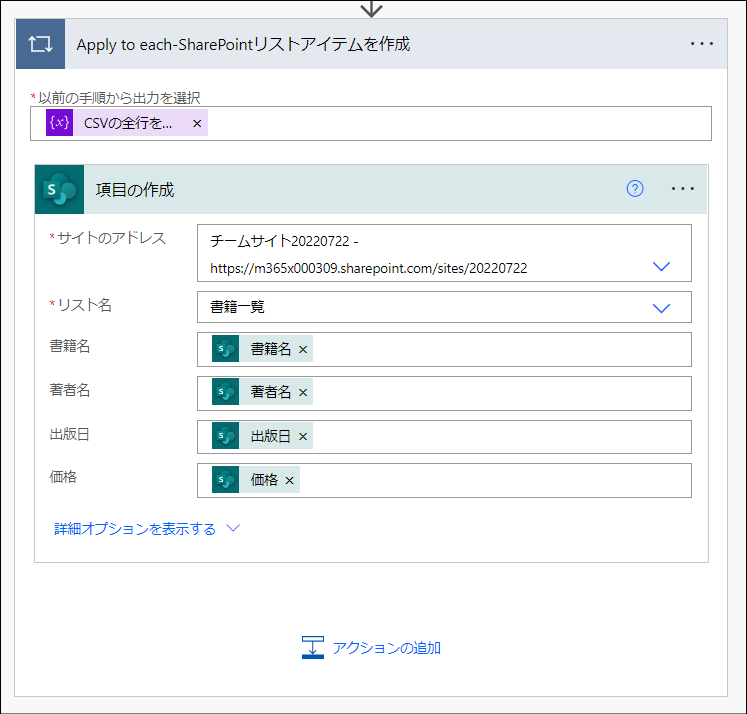
「そのJSON配列を入力としてSharePointにリストアイテムを投稿する」アクション
この章の解説対象は下図の部分です。
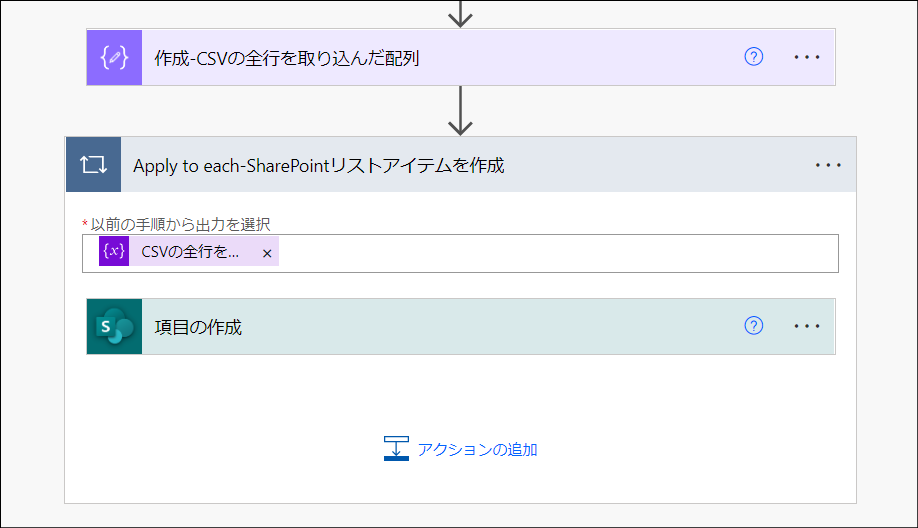
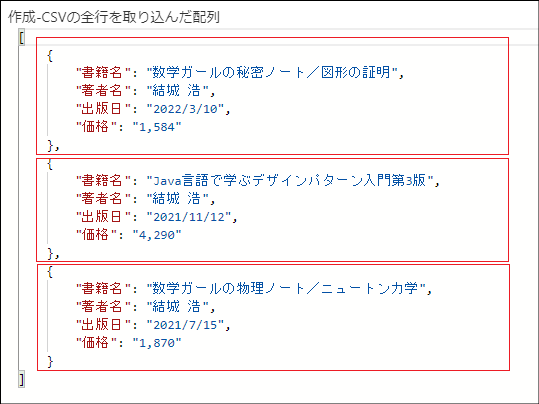
「作成-CSVの全行を取り込んだ配列」アクションは後続のアクションでSharePointリストに投稿するデータを確認するために配置しています。このアクションはフローの可読性をあげるために配置しています。フローのデータ処理には必要無いアクションであるため、このアクションを削除してもフローは正常に動作します。
次に、JSON配列を入力にして[SharePoint Online]>[項目の作成]アクションを使ってSharePointリストにアイテムを投稿します。CSVの1行につき1アイテムを投稿するため、Apply to each アクションを使った繰り返し処理をします。

最後に
「解説編その1」から一ヶ月あいてしまってすみません。
このフローについては別の投稿でもう少し補足をいれたいと思います。それがこの件です。
値がダブルクォーテーションで囲まれていたり囲まれていなかったりするCSVを配列化するために、カンマを区切り文字として使用するかどうか見きわめてsplitしてくれるフローを作った。 https://t.co/RM9fMYXP3V
— わたるふ (@wataruf01) July 25, 2022
今回は以上です。