掲題のフローの応用編その2です。応用編その1で公開したフローを解説します。
フローをGitHubで公開しました。下記リンク先からダウンロードしてください。
github.com
- 解説の経緯
- フロー図
- 解説する範囲
- 「Apply to each-行の個数だけ繰り返し処理」の概要
- 入力と出力
- 解説:CSVの行のうちデータ部分(= 2行目以降)を列項目ごとに区切って配列に変換する
- 最後に
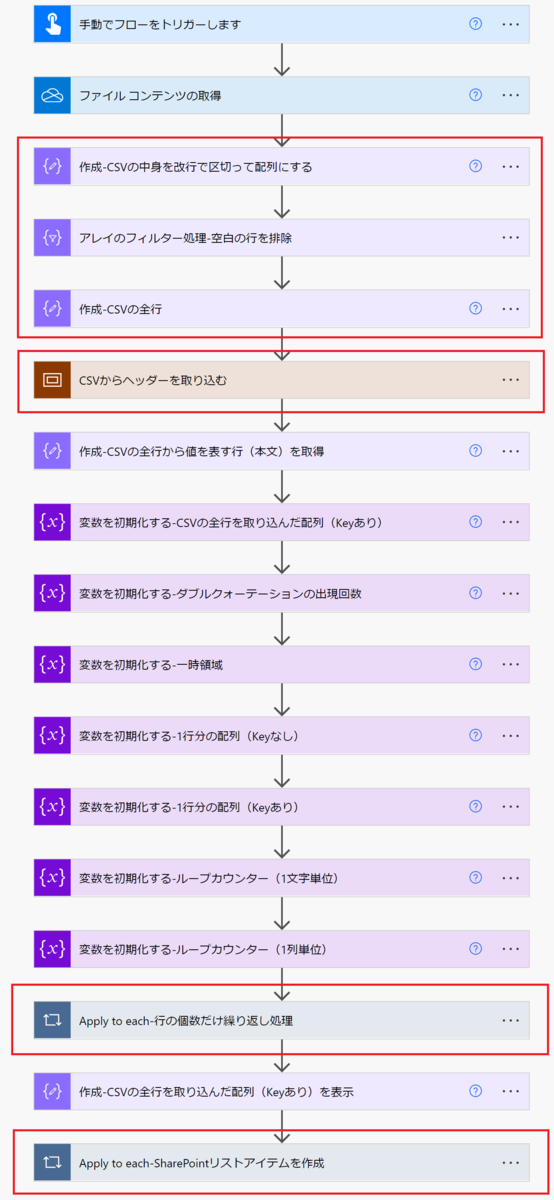
フロー図
アクションの設定を閉じた状態のフロー図
このフローで実施している処理の大項目は以下の通りです。
- CSVのデータを読み込む
- CSVの1列目をヘッダー(列名)として取り込む
- Apply to each-行の個数だけ繰り返し処理
- SharePointリストのアイテムを登録
解説する範囲
4つの大項目のうち 1・2・4は解説編で解説している内容と大きく変わりません。そのため、応用編での解説は割愛します。応用編では 3 を解説します。
- CSVのデータを読み込む (解説済み)
- CSVの1列目をヘッダー(列名)として取り込む (解説済み)
- Apply to each-行の個数だけ繰り返し処理
- SharePointリストのアイテムを登録 (解説済み)
「Apply to each-行の個数だけ繰り返し処理」の概要
このApply to each(= 繰り返し処理)は以下の2つの役割があります。
入力と出力


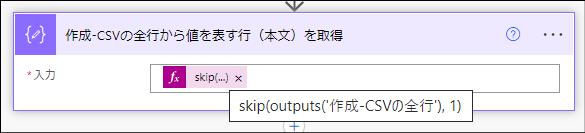

解説:CSVの行のうちデータ部分(= 2行目以降)を列項目ごとに区切って配列に変換する
フロー図の該当範囲
この処理に該当するのは下図の赤枠で囲んだ部分です。

ステップごとに解説します。
ステップごとの解説
繰り返し処理のインデクサ
この「Apply to each-行の個数だけ繰り返し処理」のインデクサはCSVの2行目以降の行を格納した配列変数です。
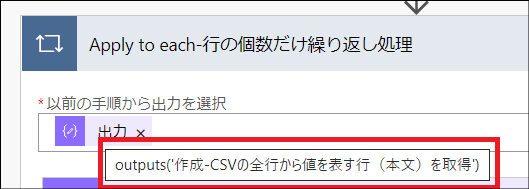
この配列変数に格納されている要素の数だけ繰り返し処理を行います。例えば、下図の場合は4行あるので繰り返し処理を4回行います。

「選択-1文字ずつ区切って配列にする」アクション
「データ操作」>「選択」アクションです。入力された文字列を1文字単位に切り分けた配列に変換します。
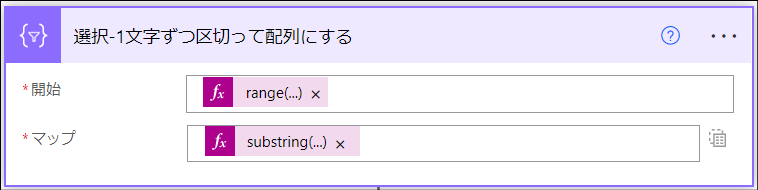
"from": "@range(0, length(items('Apply_to_each-行の個数だけ繰り返し処理')))",
"select": "@substring(items('Apply_to_each-行の個数だけ繰り返し処理'), item(), 1)"
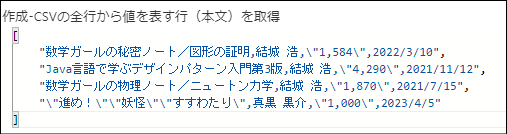
例えば入力の4行目の行に対してこの選択アクションを実行すると処理結果として下記の出力が得られます。

ちなみに、この選択アクションの使いかたは下記のQiitaの投稿で紹介いただいている手法を使用しました。この選択アクションで使っている関数の意味を紐解くと、選択アクションの本質が繰り返し処理であることが分かります。
qiita.com
「Apply to each-行の1文字ごとにループ」アクション
「コントロール」>「Apply to each」アクションです。この繰り返し処理がこの応用編のフローの最も重要な部分です。
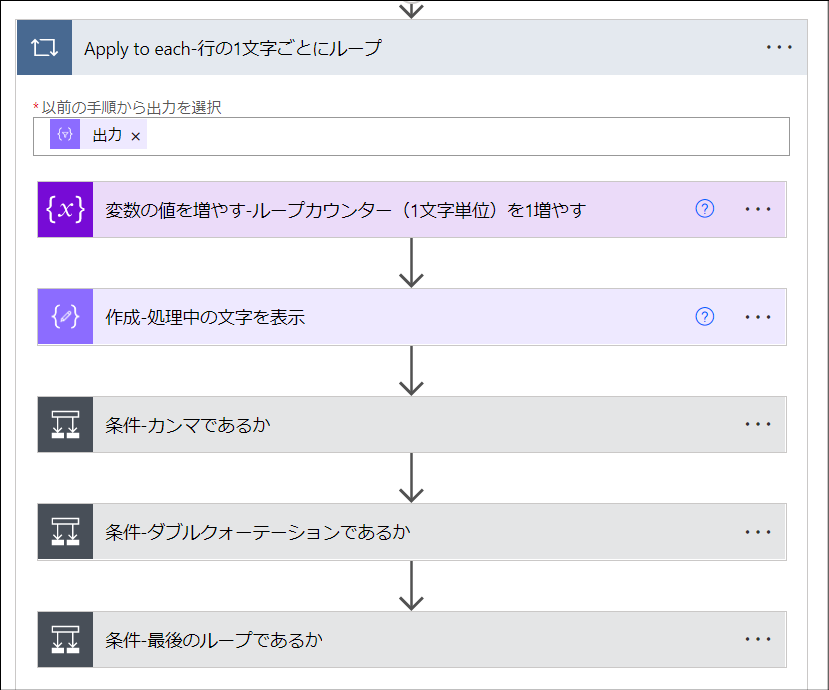
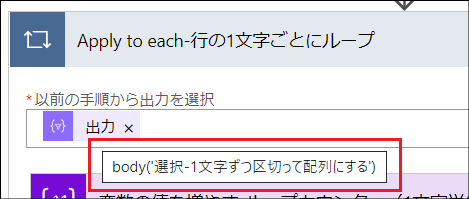
この「Apply to each-行の1文字ごとにループ」のインデクサはアクション名の通り、行の1文字1文字です。
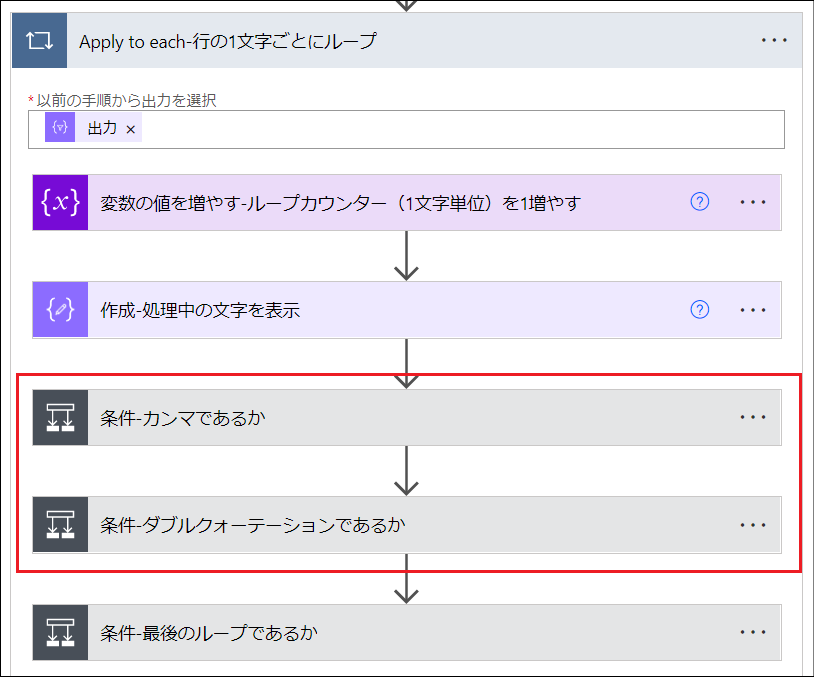
繰り返し処理のなかでその文字が「カンマであるかどうか」と「ダブルクォーテーションであるかどうか」を判定しています。それによって、その文字がCSVのデータとして扱う文字なのかそれともデータとして扱わない文字なのかを判断しています。
「Apply to each-行の1文字ごとにループ」アクションのなかみは下図の通りです。アクションごとに解説するとややこしくなるので図で解説します。興味のあるかたは図の説明とフローのアクションを見比べてみてください。
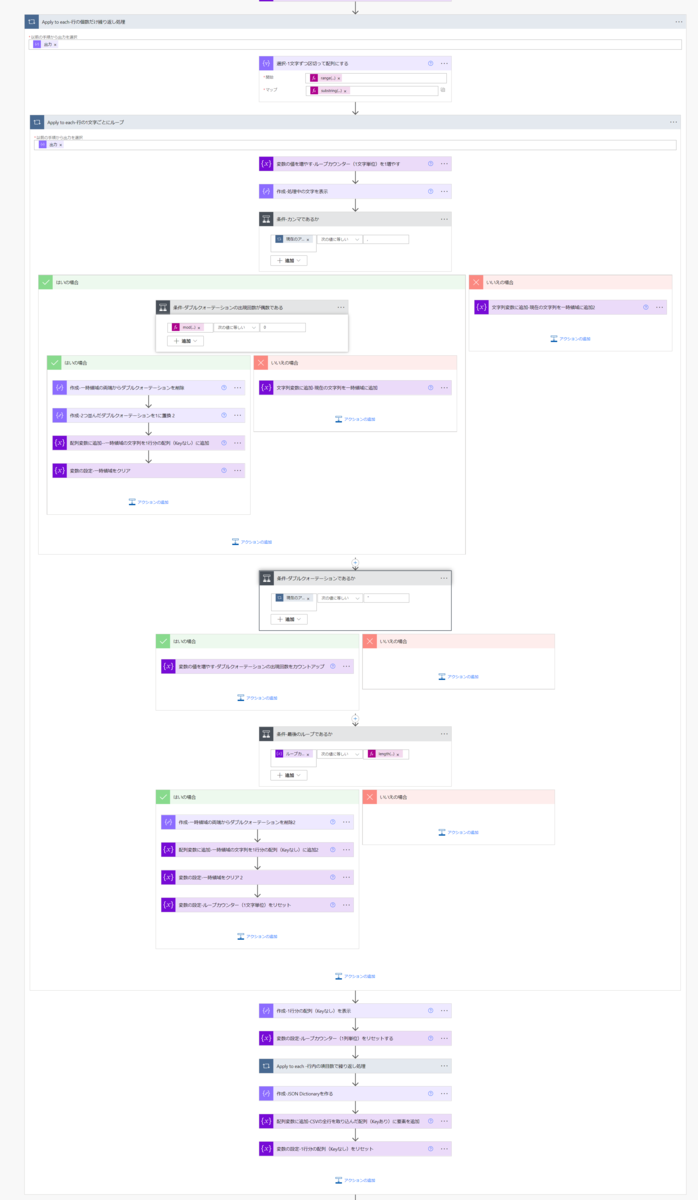
要点を一言であらわすと「ダブルクォーテーションの登場回数が奇数なのか偶数なのかによって、カンマが区切り文字であるかそれともデータとして扱う文字なのかを判断」しています。
- 登場回数が奇数である ・・・ カンマはデータとして扱う文字である
- 登場回数が偶数である ・・・ カンマは区切り文字である(= データとしては扱わない)
ここからは図で「Apply to each-行の1文字ごとにループ」内の処理の流れを説明します。
【図の説明】
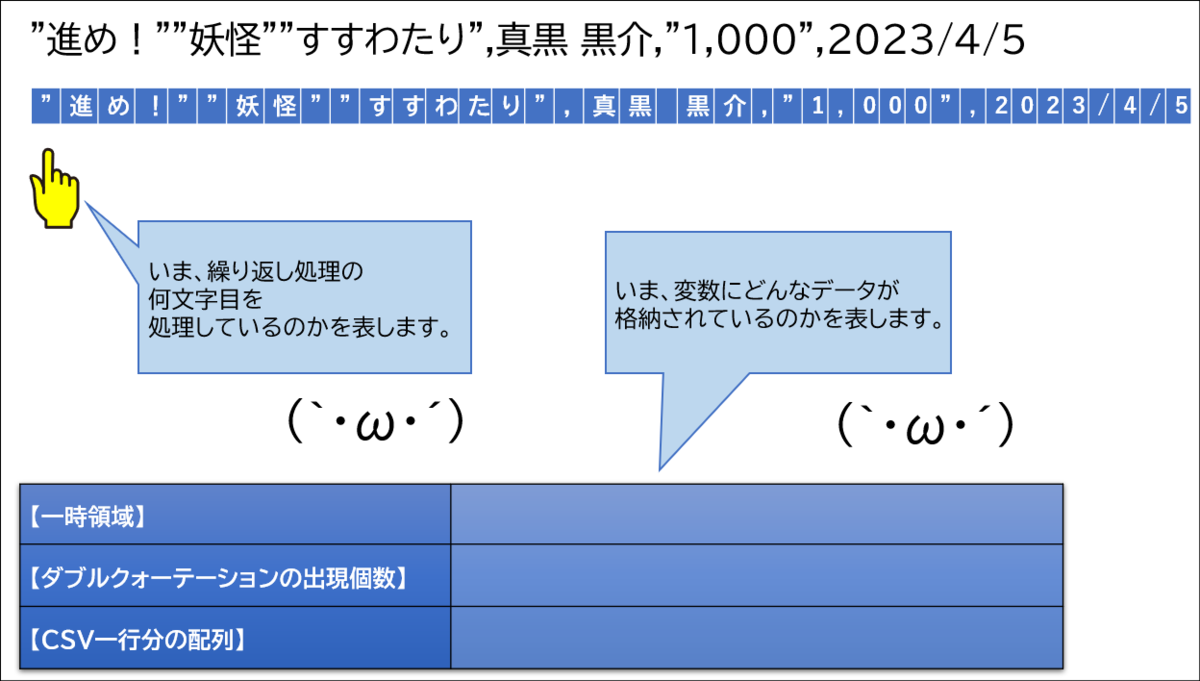
まずは1文字目です。

次に2文字目です。
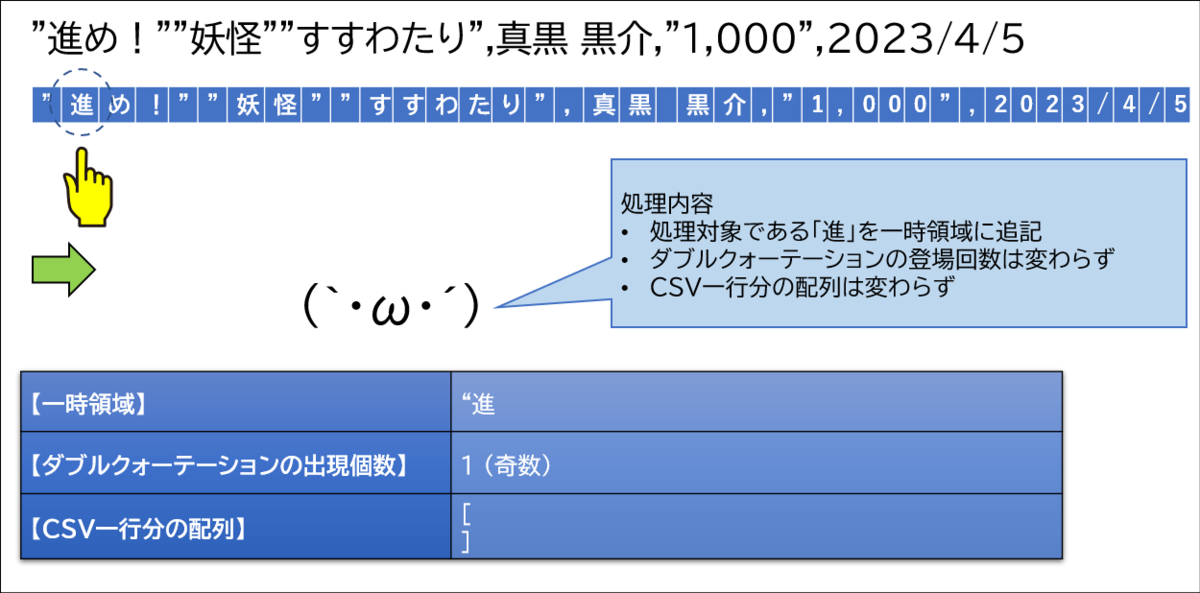
どんどん繰り替えし処理を進めていきます。5文字目でダブルクォーテーションが登場しました。なので、ダブルクォーテーションの登場回数の変数をカウントアップします。
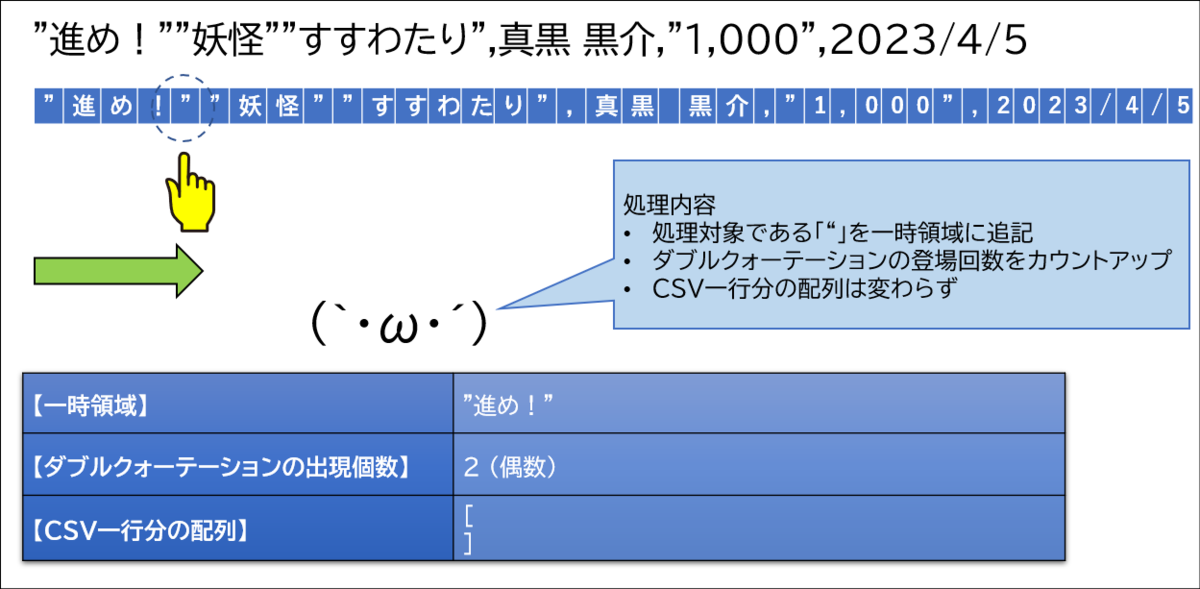
ここで初めてカンマが登場しました。この時点でダブルクォーテーションの登場回数が6回、つまり偶数です。そのため、このカンマは区切り文字であると判断します。
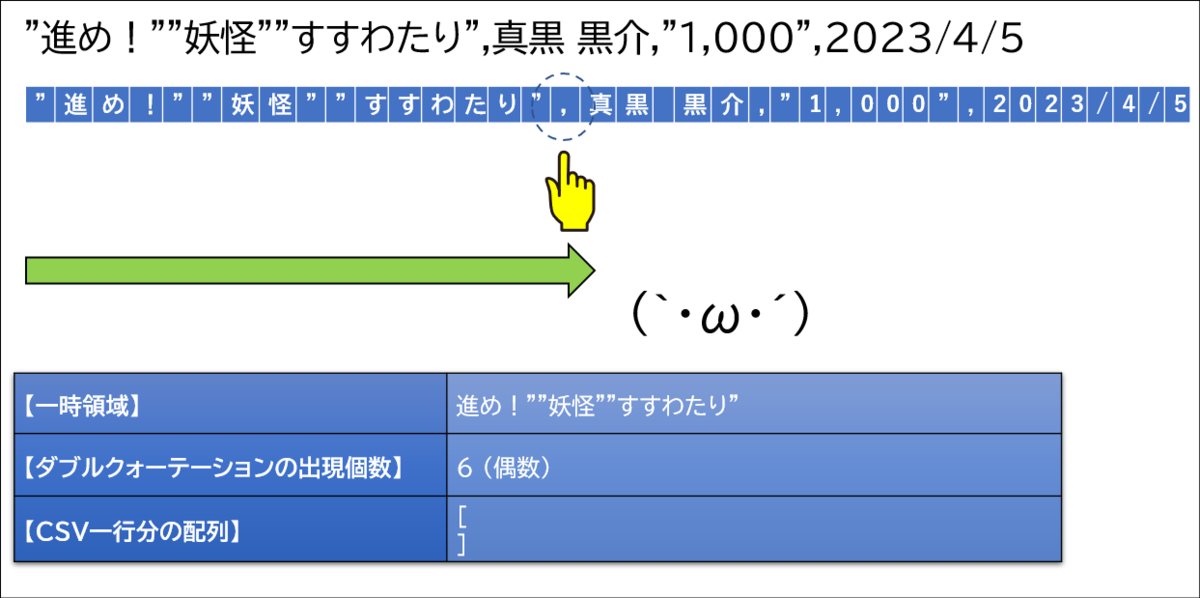

ここでまたカンマが登場しました。この時点でもダブルクォーテーションの登場回数は6回、つまり偶数です。そのため、このカンマも区切り文字です。
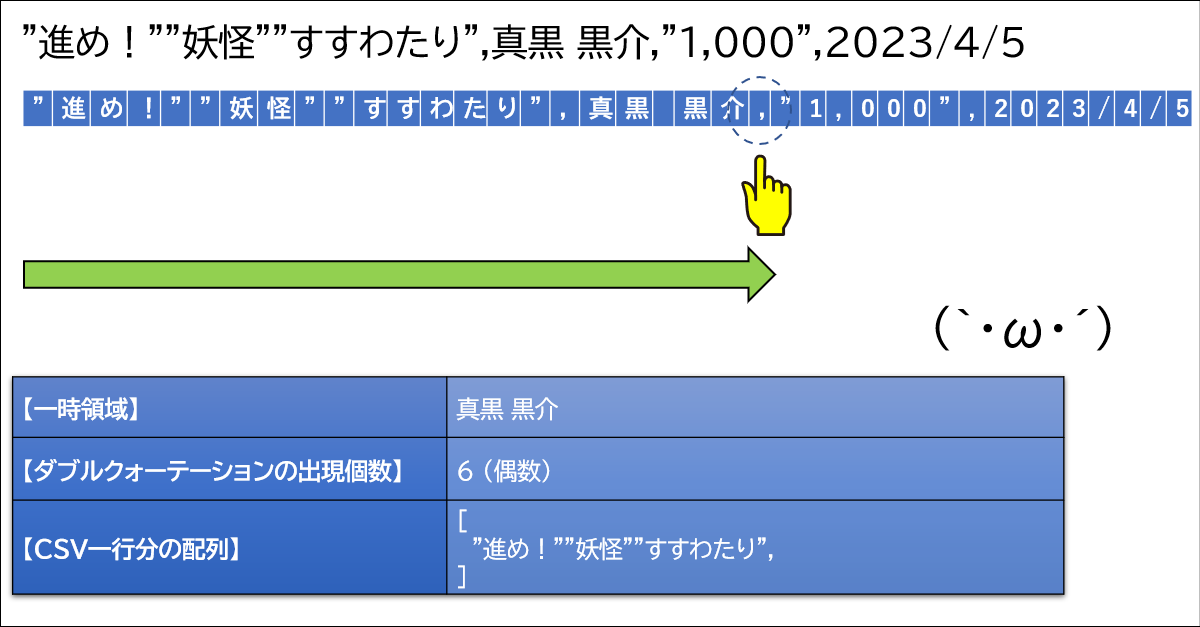
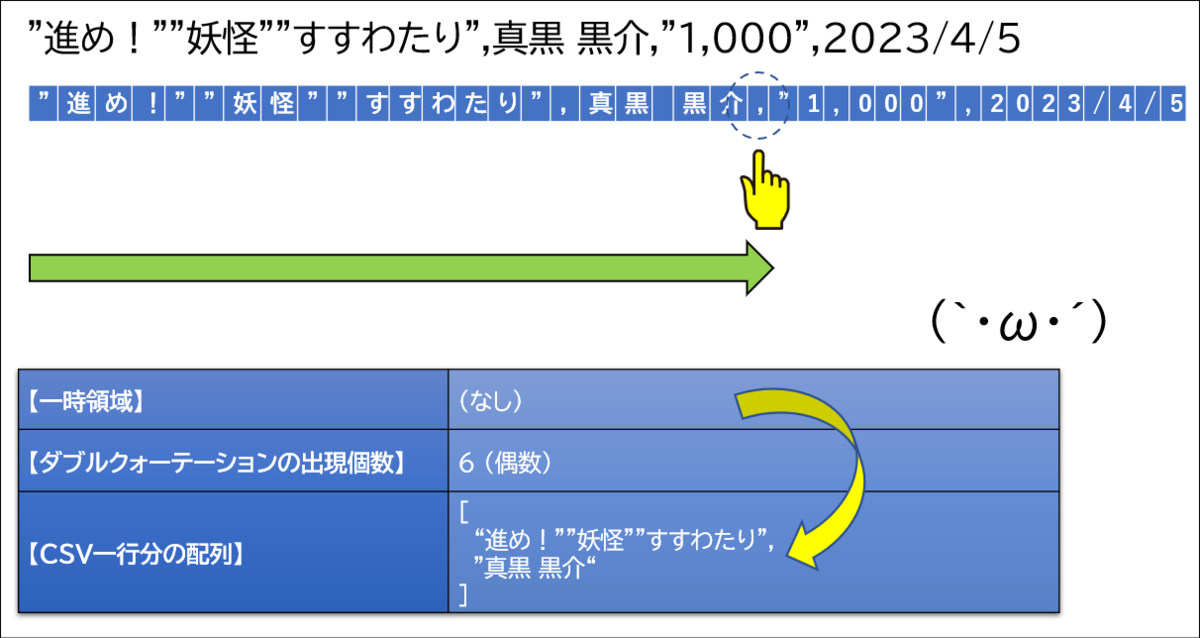
ここでまたカンマが登場しました。この時点でダブルクォーテーションの登場回数は7回、つまり奇数です。そのため、このカンマはデータに含まれる文字です。
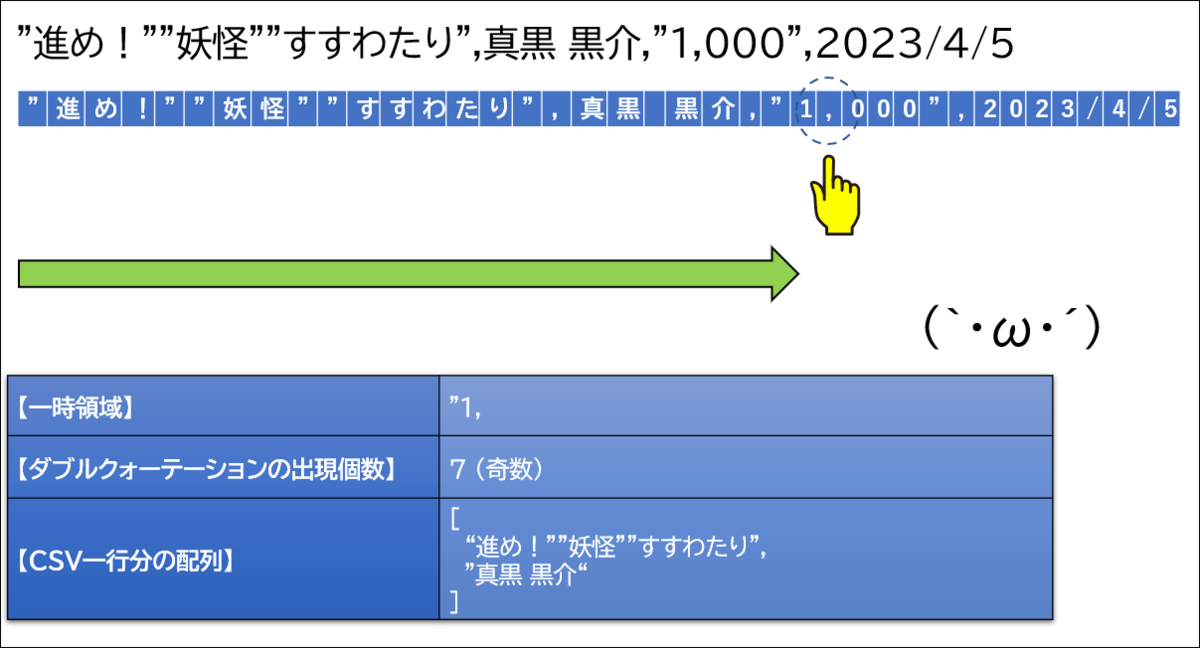
ここでまたカンマが登場しました。ダブルクォーテーションの登場回数は8回、つまり偶数です。そのため、このカンマは区切り文字です。「1,000」を配列に追加します。この際、両端のダブルクォーテーションは関数によって取り除いています。


繰り返し処理の終端まで到着しました。この時点で【一時領域】に格納されている文字列は分岐条件「最後のループであるか」による処理で配列に追加します。
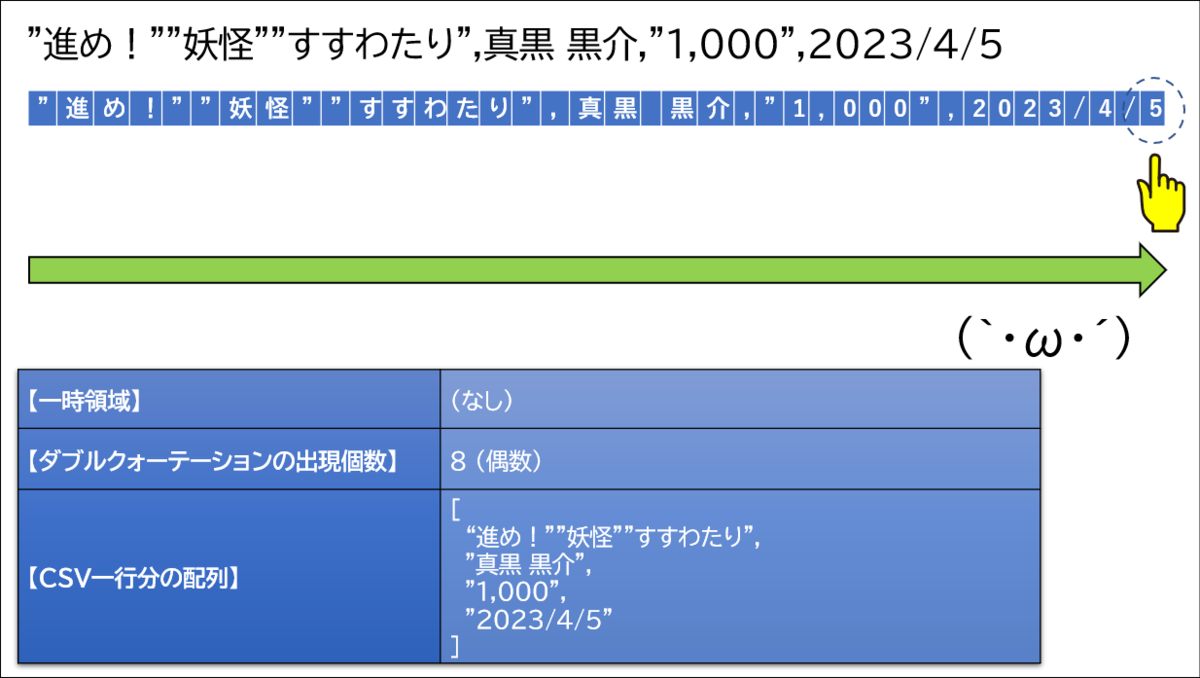
これでCSVの1行を配列にすることができました。
(`・ω・´)シャキーン



最後に
応用編その1 でも記載したとおり、このフローは処理内容がとても遅いです。そのため本番運用でこのフローが活用できるケースは限定的だと思います。
なので、フローの配列操作のパターンとして「こんなこともできるんだ」と思いながら読んでもらえれば幸いです。
( ゚Д゚)
今回は以上です。